Posted inConference Cryptography Tutorial
A Brief Introduction to BitCoin and BlockChain
I recently had a talk about BitCoin and mainly BlockChain technology at Application of New Generation…

Personal Website

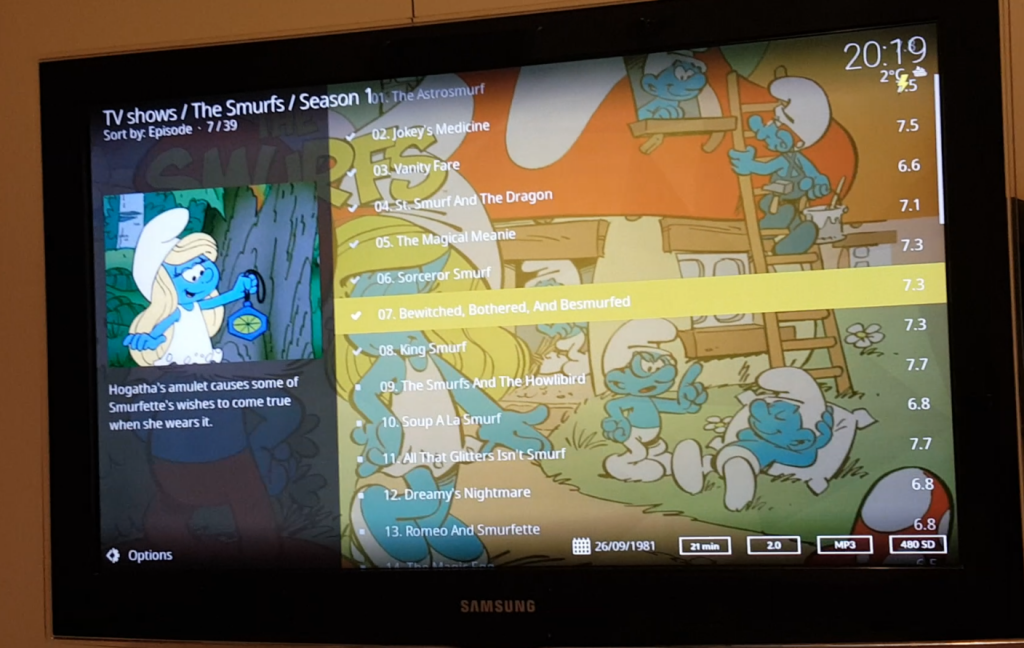
I’ve posted about creating a media home system using Kodi sometimes ago.
After that I configured Kodi on my Laptop and Smart phone which they use the same database shared in home network.
Now, with the help of a small TV card, I’ve added live TV feature to the whole media home.
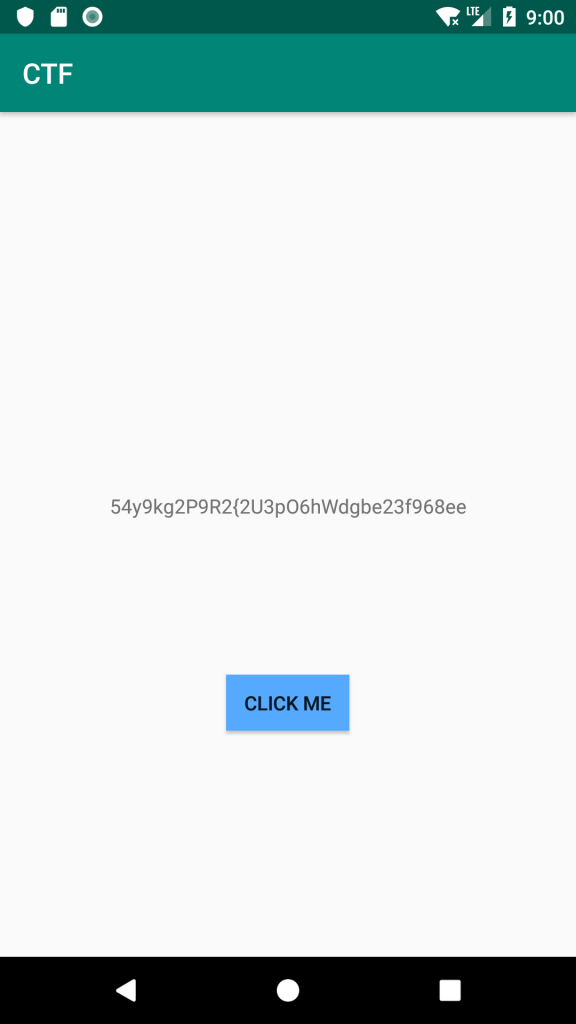
Ilam CTF has been hold on 23rd Nov 2018. Unfortunately I’ve planned other things for 22-23 Nov 2018 and because of the delay in holding the CTF, I couldn’t attend this CTF.
However, I could download the Android Reverse question for future analysis. And the flag is here:
ilam_ctf_0a095194dbcf4f798751aaafdfb_1db6b2ed339f4698b6b38b5e7ae
But the WriteUP!

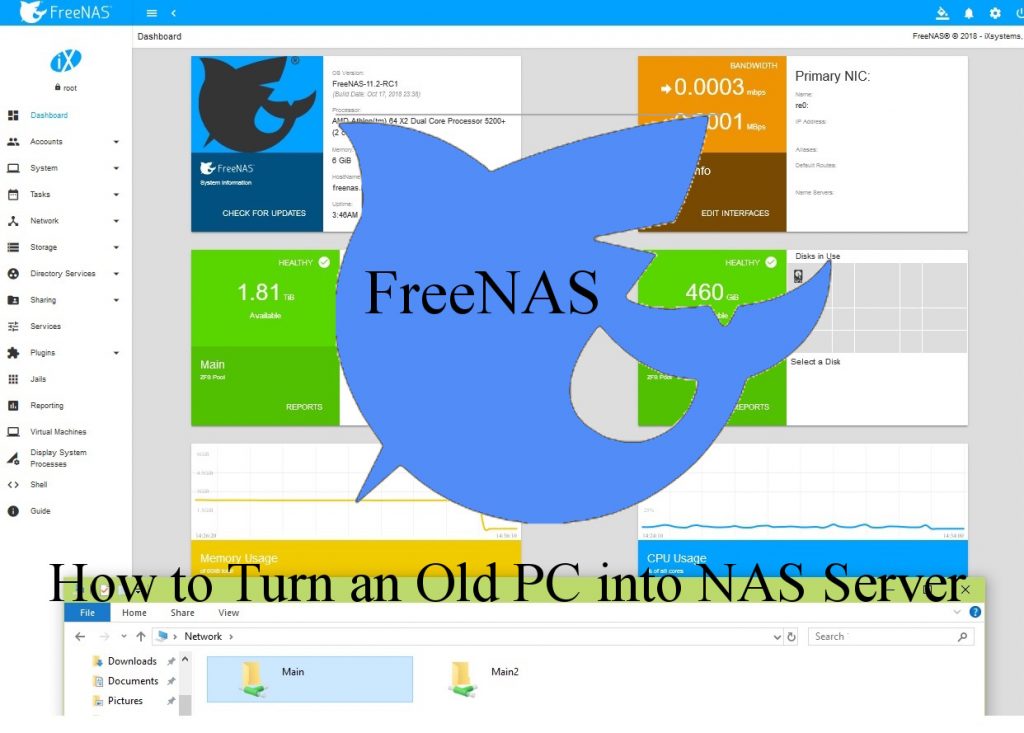
Recently, I collected my old Hard drives (and CD/DVD writers) and packed them into my OLD Computer Case in order to create home NAS . Then I’ve installed FreeNAS on it and everything is OK. 🙂
FreeNAS is the simplest way to create a centralized and easily accessible place for your data
Following, the construction steps are presented.

In this post, I’m going to write about the one day cyber-security conference which was held by Urmia University of Technology, named Protective and Operational Security (P0SCon).

I’ve playing with Android CTF questions recently and found this jewelry box. One of the questions was about a numeric one way hash question named NUMDROID. The question was presented in ASIS2014 and here, I write the write-up!

I recently established a wired connection into my server through my computer. I’ve mixed the protocols (OpenVPN, TOR, SOCKS) to RE-ANONIMIZE myself! I’ve put “The Good, The Bad and The Ugly” name on the scenario. Here is a very good picture of it!
I’ve started a project named Onion Harvester for finding the Onion addresses in TOR hidden services which are not exposed by the owners. I believe that the real dark markets and interesting stuff of TOR networks relies in the dark.

This the second and final writeup of Android challenges which was given in 8st Sharif CTF. I’ve wrote about the team and place in the 8st SharifCTF Android WriteUps: Vol I. The writeup begins …