Posted inAnonymity Networks Cryptography Tutorial
Configuring a Hidden Email Server
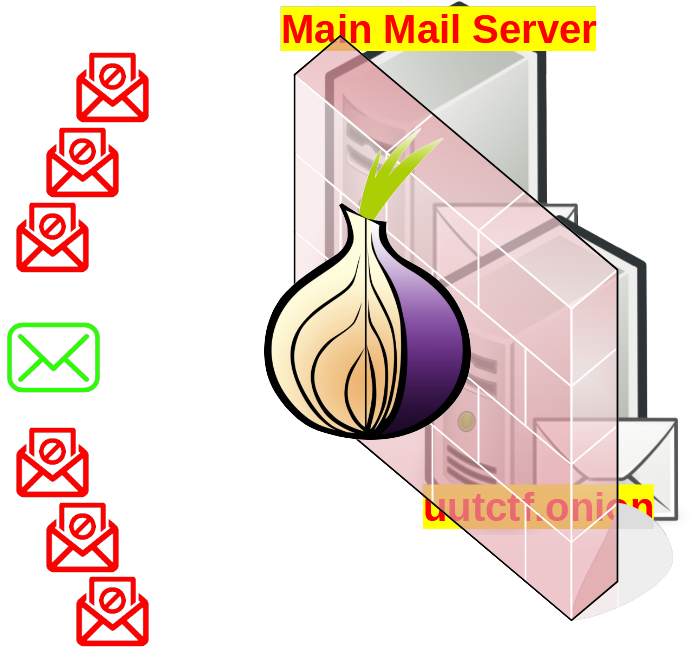
In this post, I will talk about configuring an Email server which is accessible using TOR. Using TOR will make its IP to be hidden, also accessible if it is behind NAT (inside a home computer without a public IP). But the main question is why one should use this kind of scenario?
Many people may not trust messaging services such as Telegram or WhatsApp but want to have their own private communication system. In this tutorial, you can run your own mail server in your home LAN and access it through Internet without spending money for public IP or VPS.
For the email server part, I will use hMailServer, an open source email server developed for windows.