Posted inServer
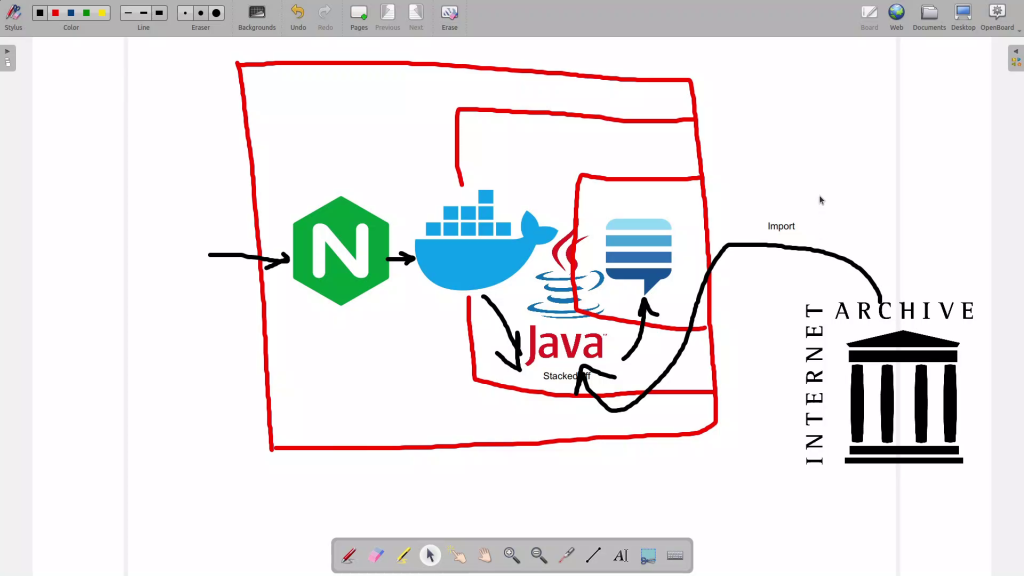
Self Hosted Stack Exchange
In this video, I’m diving deep into deploying a self-hosted, offline version of Stack Exchange dumps using the powerful StackedOff tool. Imagine having access to the vast knowledge base of Stack Exchange including Stack Overflow, even when your internet connection is down. No more frantic searches for “how to connect to the internet” while trying to debug your code!