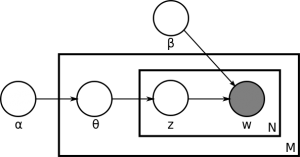
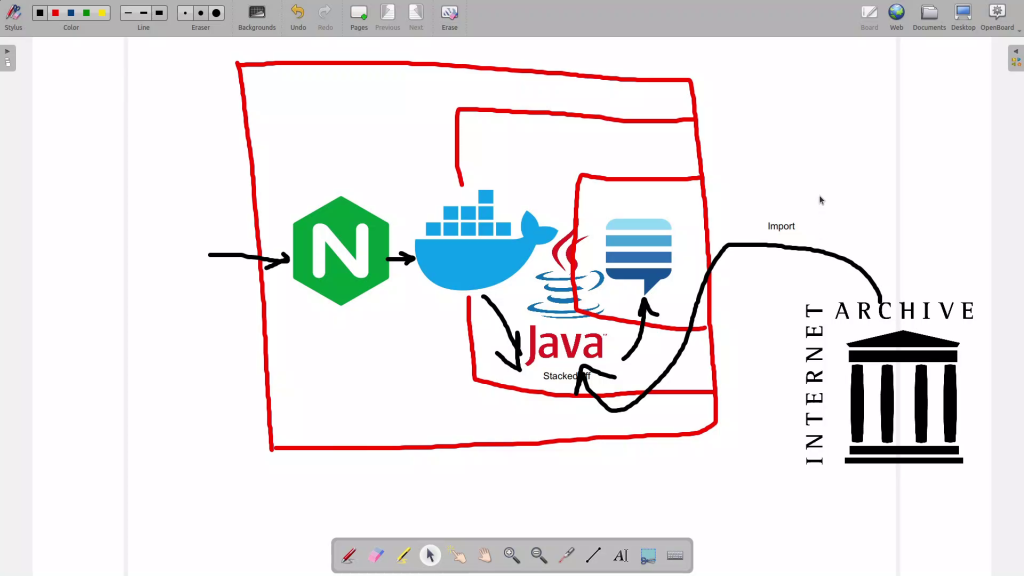
How to turn your TV to Media Center
You may be like to collect and watch movies, TV series, or music archives. Then you have to store them in your storage ([External] Hard drives, NAS, …) and use some software to manage them.
However the scenario sounds good but there are other great ways to turn your home network to a full capable media center. Read more to learn how to configure and change your home network to media center.