
What is Latent Dirichlet Allocation?
In a general view, LDA is an unsupervised method for clustering documents. It models (purified) documents as bag of words. Also it assumes each word (and document) has a mixture model of topics i.e. each word (and document) may belongs to each of the topics by a probability. It takes number of clusters in the corpus as input then, simply assigns each word in each document a random topic. Then tries for
It was a very general description of LDA.
How it is work?
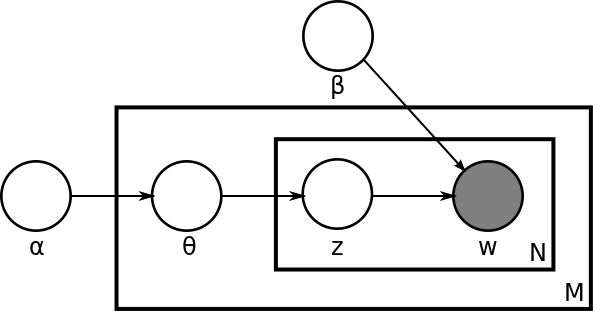
The process of LDA depends on the bag of words model of documents. First of all there are K topics that is input of LDA (guessed!). We have totally D documents and V distinct vocabulary in the document set. The generative process is:
- For k = 1 … K:
- φ(k) ∼ Dirichlet(β)
- For each d in D:
- Θd ∼ Dirichlet(α)
- For each word wi in d
- zi ∼ Discrete(θd)
- wi ∼ Disctete(φ(zi))
This is the total process. But what it means?
Dirichlet
In simple words, Dirichlet is a probabilistic distribution that has K concentration parameters. Each parameter (α) is a random number greater than zero (α > 0). Following is an example of Dirichlet distribution for 20 documents with 4 topics. Parameters for this example (α1 = 10, α2 = 5, α3 = 3, and α4 = 20).

φ(k)
This is a Dirichlet distribution for the Kth topic. The φ is a KxV matrix where each element is the probability of belonging the vth word to the kth topic.
Θd
Similarly the Θd is a Dirichlet for the document d. It shows the belonging of the document to each of the topics.
Finally
The process is as below in simple words:
- For each topic:
- Randomly initialize belonging probability of each word in vocabulary to the topics.
- For each document:
- Randomly initialize belonging probability of current document to the topics.
- For each word:
- Choose a topic from Θd (zi)
- Randomly choose a new word from φ(k) where k is the selected topic in the previous part.
The last step, helps us to find words similar to the current chosen one to be in same cluster.
In the next post, I will explore the mathematics behind the LDA. Any comments?
