Library and Book management is one of my favorite hobbies. I like to categorize (e)books, Albums, and Movies. It is more better if the contents are in my profession, IT!
Recently I and two of my students, have managed lots of IT Ebooks which I am going to tell it’s story.
Each electronic collection is made up 3 main steps:
- Crawling the content
- Purifying the content
- Add more information to the content
Crawling the Content
For crawling the Elibrary content, I’ve choose ALLITEBOOKS.com which is a very up to date and has lots of IT ebooks. Mohammad Niazmandan and Alireza Shams, two of my students in Information Retrieval course, worked on crawling and downloading the content. After crawling 6545 ebooks and their metadata has been downloaded. The total size of the ebooks is 94.7 GB.

Purifying the Content
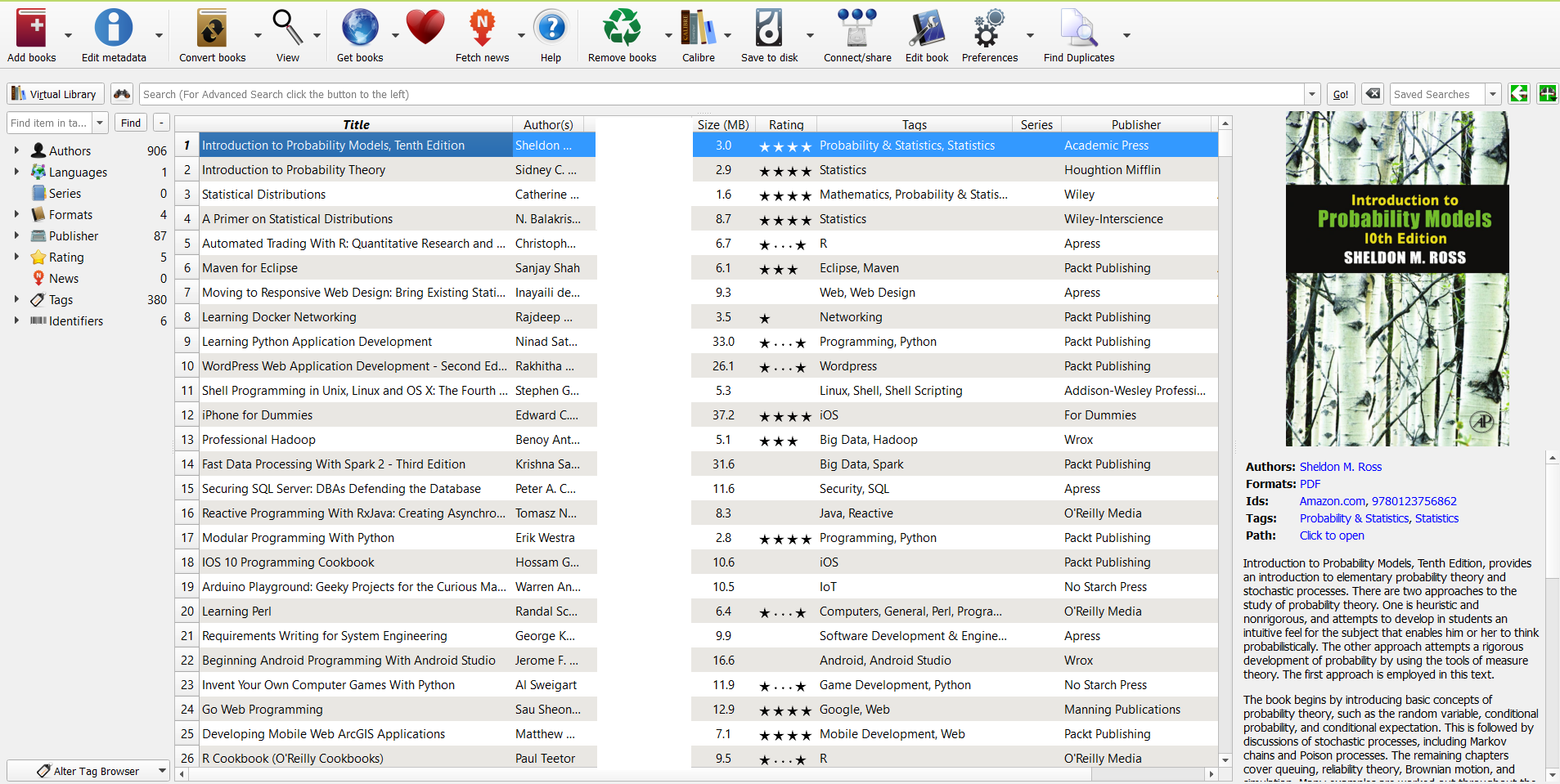
After having the books, it is turn of purifying the content. Calibre is one of my favorite library managers! It is Open Source, free, Python based and multi platform! Here is a shot from my calibre:
For purifying the content, firstly I’ve made a simple HTML parser to grab ISBN and tags from AllITEbooks book detail pages. Then add them to my calibre library using command line:
calibredb add --isbn ISBN_Of_The_Book --tags "TAG1,TAG2,TAG3" THE_BOOK.pdf
This will add all the books with ISBN and tags metadata to calibre.
Add More Information to the Content
Till now all the books are added to calibre and are pretty good! But having more meta data and details are appreciated. Thanks again Kovid Goyal for the Bulk Metadata Update feature of the calibre. It works nice but sometimes have problem with file names, specially when the title comes with #, ++ or etc. It is common in IT and Computers, for example Learning C#. So I decided to add the ebooks with only ISBN which always works.
The only step is to update calibre with Auto Meta Data. That’s All!