In this tutorial I want to write about using Apache Spark on Ubuntu machines where you can develop big data analysis apps with it.
First of all, I want to write a small and quick introduction to Hadoop + Spark environment. Hadoop makes it possible to work with lots of computers in a cluster. Work can be: storing files in cluster (HDFS – Hadoop Distributed File System), storing database in cluster (Apache HBase), or run software in cluster (MapReduce, Spark).
In Hadoop there is a master node who controls clients inside clusters and partition the data between them.
I do not want to talk about how to configure Hadoop + Spark in Linux. There is a nice tutorial which I followed and configured two machines (1 master + 1 slave). Here is the link. Thanks to Sumit Chawla.
Firstly I’ve configures my master node: Ubuntu 14.04 + Java Oracle 8 + Virtual Box

After that I’ve created my slave01 node which was a clone of master node. There is a good tutorial on how to clone virtual machines using VirtualBox in this link. Actually I’ve changed some configuration in slave including user name and display name. Here is a screenshot of slave01:

After that it is time to start HDFS + YARN + SPARK in master node. Commands are here:<br /><br />
$HADOOP_HOME$/sbin/start-dfs.sh
$HADOOP_HOME$/sbin/start-yarn.sh

And finally start Spark:
$SPARK_HOME$/sbin/start-all.sh

And control in both master and slave01 that daemons are running using jsp:

Everything is OK. You can check the spark WebUI in http://127.0.0.1:8080 and HDFS in http://127.0.0.1:50070 from master node.
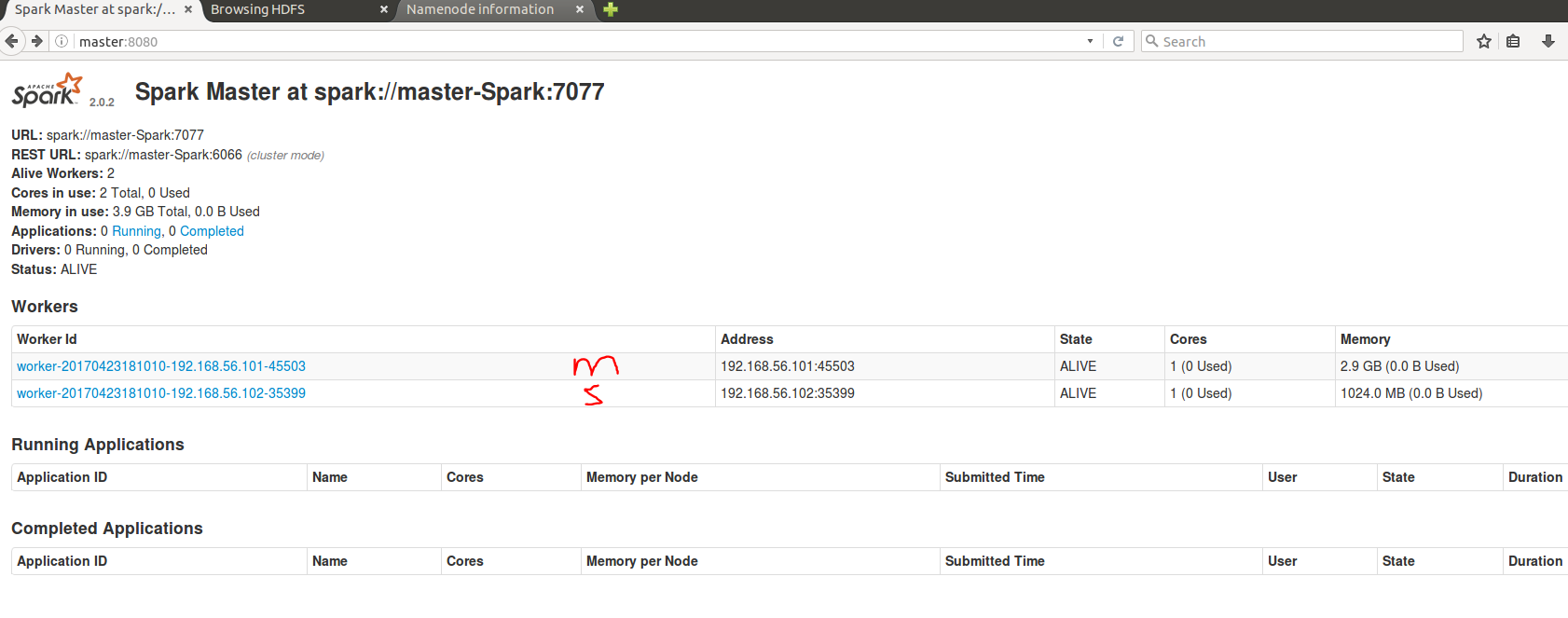
I showed master with m and slave node with s [ It seems to be s 🙂 ]

It is time to programming. The main concept in MapReduce or Spark programming is (key, value). The main jobs is to read data from file (or HDFS) line by line. Process the lines by Map and create 0 or 1 or many (key, value) pairs. Hadoop will collect and sort the pairs with same key and give them to Reducer. Now reducer can decide what to do with the values. In the popular example of word count, the reducer sums all 1s to produce the word count.
I’ve developed with Java. I’ve installed Netbeans on master node and added libraries for Spark programming from $SPARK_HOME$/jars directory.
/**
* private static void cooccurenceCount(String inputFile, String outputFile) {
* // Define a configuration to use to interact with Spark
* SparkConf conf = new SparkConf().setAppName("Cooccurence Count App");
*
* // Create a Java version of the Spark Context from the configuration
* JavaSparkContext sc = new JavaSparkContext(conf);
*
* // Load the input data, which is a text file read from the command line
* JavaRDD<String> input = sc.textFile(inputFile);
*
* // Java 8 with lambdas: split the input string into words
* JavaRDD<String> words = input.flatMap((String t) -> {
* JSONObject jobj = new JSONObject(t);
* String text = String.valueOf(jobj.get("Text"));
* String[] outputString = new String[text.split(" ").length * (text.split(" ").length - 1)];
*
* int counter = 0;
*
* for (int i = 0; i < text.split(" ").length; i++) {
* for (int j = i + 1; j < text.split(" ").length; j++) {
* outputString[counter++] = text.split(" ")[i] + ":" + text.split(" ")[j];
* }
* }
* return Arrays.asList(outputString).iterator();
* });
*
* // Java 8 with lambdas: transform the collection of words into pairs (word and 1) and then count them
* JavaPairRDD<String, Integer> counts = words.mapToPair(t -> new Tuple2(t,1)).reduceByKey((x, y) -> (int)x + (int)y);
*
* // Save the word count back out to a text file, causing evaluation.
* counts.saveAsTextFile(outputFile);
* }
*/
In the code above, I have parsed the data which is read from HDFS line by line and parsed JSON. Here is a part of my input file:

After that I create pairs of each tweet by its words to find their sequential co-occurrence. For example for the last tweet seen in the above:
(employs:people,1)
(employs:green,1)
(employs:nationality,1)
(people:green,1)
(people:nationality,1)
(green:nationality,1)
After compiling the source code to jar, I’ve copied the jar file on all machines (/tmp/tmp/TweetCount.jar) and start to mine them with the following command:
/** * ./spark-submit --master spark://master:6066 --deploy-mode cluster /tmp/tmp/TweetCount.jar hdfs://master:9000/test/data.txt hdfs://master:9000/test/output_Twitter_COOCCURENCE/ */
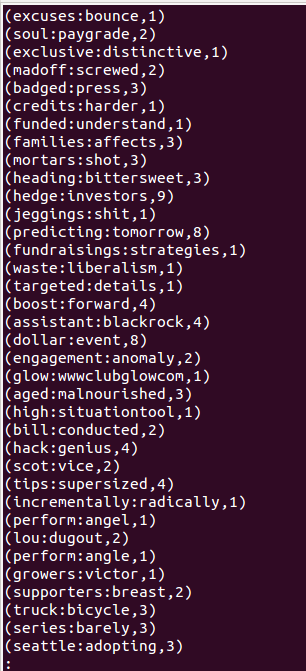
And vola! Everything is OK and after executing, output is in HDFS /test/output_Twitter_COOCCURENCE.

The output of a sample file (part-00002) is displayed below: